Descubre cómo los Init Containers pueden proporcionar capacidades adicionales a tus cargas de trabajo en Kubernetes

Hay muchos nuevos desafíos que vienen con el nuevo patrón de desarrollo de una manera mucho más distribuida y colaborativa, y cómo gestionamos las dependencias es crucial para nuestro éxito.
Kubernetes y las distribuciones dedicadas se han convertido en el nuevo estándar de implementación para nuestra aplicación nativa de la nube y proporcionan muchas características para gestionar esas dependencias. Pero, por supuesto, el recurso más habitual que utilizarás para hacer eso son las sondas.
Kubernetes proporciona diferentes tipos de sondas que permitirán a la plataforma conocer el estado de tu aplicación. Nos ayudará a saber si nuestra aplicación está «viva» (sonda de vivacidad), ha sido iniciada (sonda de inicio) y si está lista para procesar solicitudes (sonda de preparación).
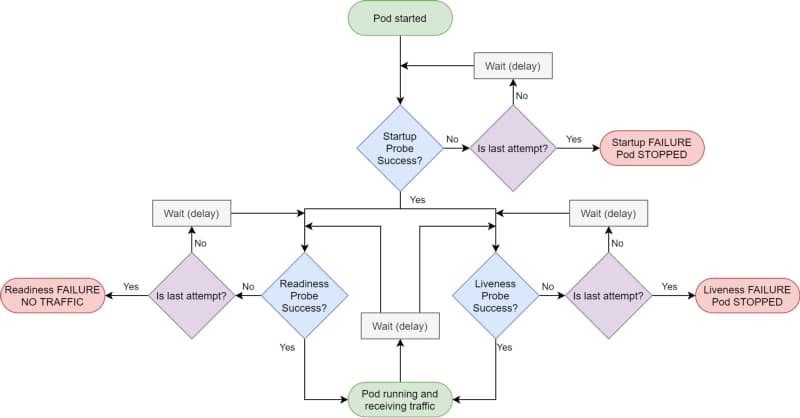
Las sondas de Kubernetes son la forma estándar de hacerlo, y si has implementado alguna carga de trabajo en un clúster de Kubernetes, probablemente hayas usado una. Pero hay ocasiones en las que esto no es suficiente.
Eso puede ser porque la sonda que te gustaría hacer es demasiado compleja o porque te gustaría crear algún orden de inicio entre tus componentes. Y en esos casos, confías en otra herramienta: los Init Containers.
Los Init Containers son otro tipo de contenedor en el que tienen su propia imagen que puede tener cualquier herramienta que puedas necesitar para establecer los diferentes chequeos o sondas que te gustaría realizar.
Tienen las siguientes características únicas:
- Los init containers siempre se ejecutan hasta completarse.
- Cada init container debe completarse con éxito antes de que comience el siguiente.
¿Por qué usarías init containers?
#1 .- Gestionar Dependencias
El primer caso de uso para utilizar init containers es definir una relación de dependencias entre dos componentes como Deployments, y necesitas que uno comience antes que el otro. Imagina la siguiente situación:
Tenemos dos componentes: una aplicación web y una base de datos; ambos se gestionan como contenedores en la plataforma. Así que si los implementas de la manera habitual, ambos intentarán comenzar simultáneamente, o el programador de Kubernetes definirá el orden, por lo que podría ser posible que la aplicación web intente comenzar cuando la base de datos no esté disponible.
Podrías pensar que eso no es un problema porque para eso tienes una sonda de preparación o de vivacidad en tus contenedores, y tienes razón: el Pod no estará listo hasta que la base de datos esté lista, pero hay varias cosas a tener en cuenta aquí:
- Ambas sondas tienen un límite de intentos; después de eso, entrarás en un escenario de CrashLoopBack, y el pod no intentará comenzar de nuevo hasta que lo reinicies manualmente.
- El pod de la aplicación web consumirá más recursos de los necesarios cuando sabes que la aplicación no comenzará en absoluto. Así que, al final, estás desperdiciando recursos en el proceso.
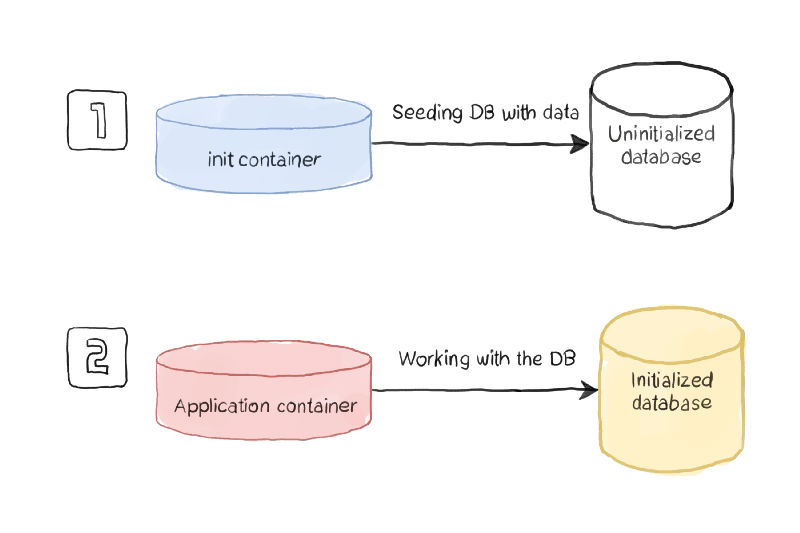
Por lo tanto, definir un init container como parte de la implementación de la aplicación web que verifique si la base de datos está disponible, tal vez solo incluyendo un cliente de base de datos para ver rápidamente si la base de datos y todas las tablas están adecuadamente pobladas, será suficiente para resolver ambas situaciones.
#2 .- Optimización de recursos
Una cosa crítica cuando defines tus contenedores es asegurarte de que tienen todo lo que necesitan para realizar su tarea y que no tienen nada que no sea necesario para ese propósito.
Así que en lugar de agregar más herramientas para verificar el comportamiento del componente, especialmente si esto es algo para gestionar en momentos específicos, puedes descargar eso a un init container y mantener el contenedor principal más optimizado en términos de tamaño y recursos utilizados.
#3.- Precarga de datos
A veces necesitas realizar algunas actividades al inicio de tu aplicación, y puedes separar eso del trabajo habitual de tu aplicación, por lo que te gustaría evitar el tipo de lógica para verificar si el componente ha sido inicializado o no.
Usando este patrón, tendrás un init container gestionando todo el trabajo de inicialización y asegurando que todo el trabajo de inicialización se haya realizado cuando se ejecute el contenedor principal.
¿Cómo definir un Init Container?
Para poder definir un init container, necesitas usar una sección específica de la sección de especificaciones de tu archivo YAML, como se muestra en la imagen a continuación:
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command: ['sh', '-c', 'echo ¡La aplicación está en ejecución! && sleep 3600']
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo esperando a myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo esperando a mydb; sleep 2; done"]Puedes definir tantos Init Containers como necesites. Sin embargo, notarás que todos los init containers se ejecutarán en secuencia como se describe en el archivo YAML, y un init container solo puede ejecutarse si el anterior se ha completado con éxito.
Resumen
Espero que este artículo te haya proporcionado una nueva forma de definir la gestión de tus dependencias entre cargas de trabajo en Kubernetes y, al mismo tiempo, también otros grandes casos de uso donde la capacidad del init container puede aportar valor a tus cargas de trabajo.