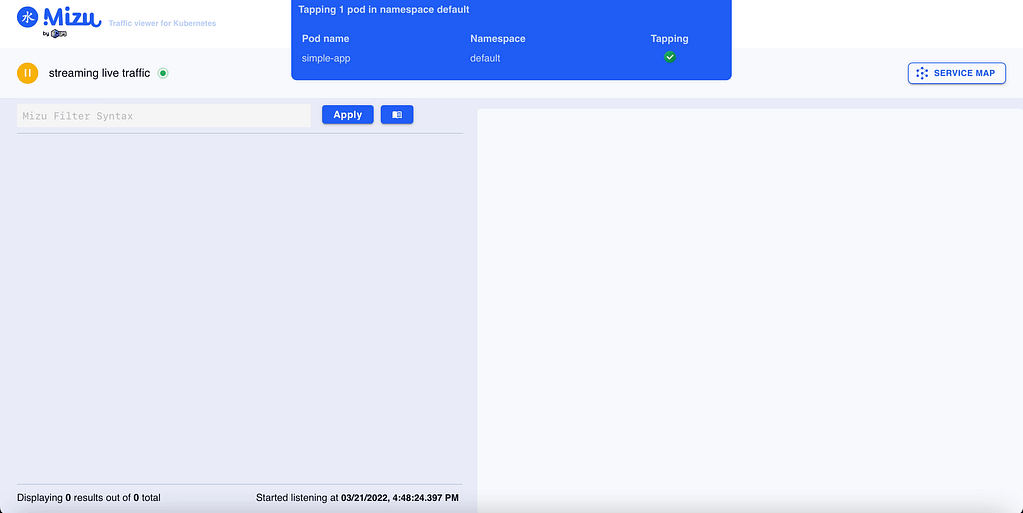
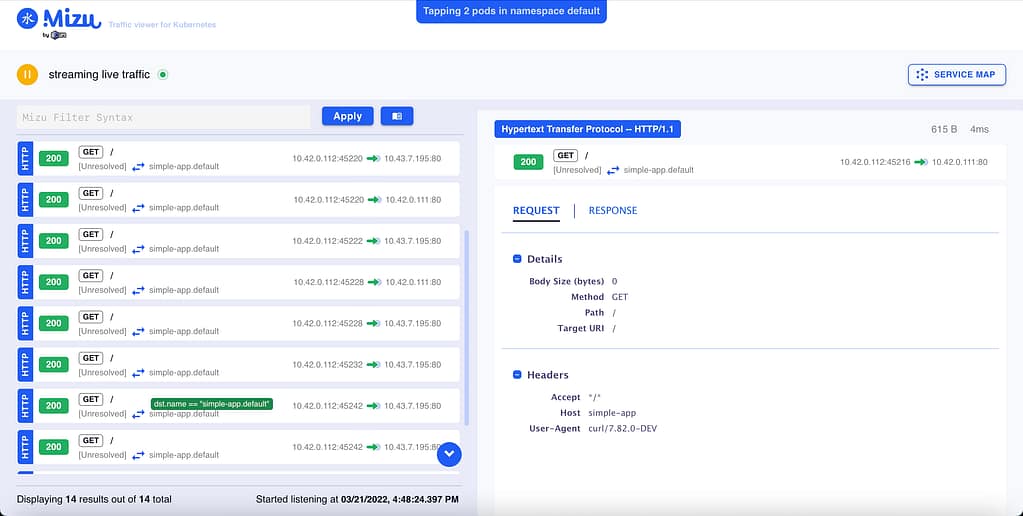
Descubre cómo extraer toda la información disponible para inyectarla en tus pods

Foto de James Harrison en Unsplash
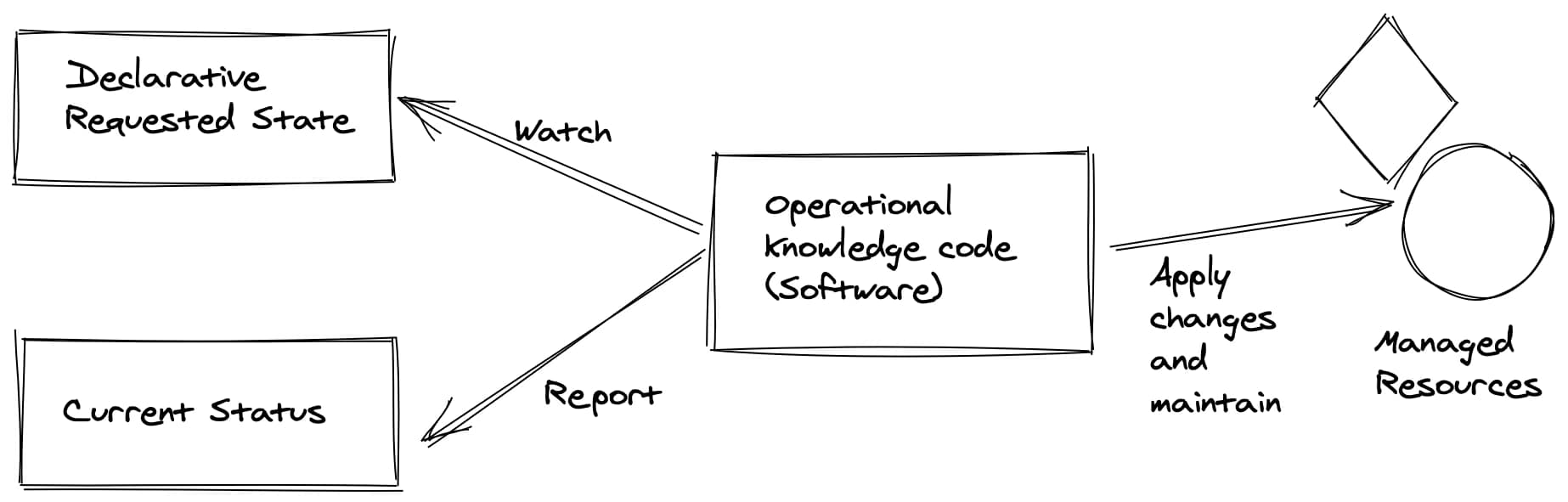
La metadata de Kubernetes es cómo accederás a parte de la información de tus pods en tu aplicación en tiempo de ejecución. Cuando te mueves de un tipo de desarrollo tradicional a uno nativo de la nube, usualmente necesitas acceder a alguna información disponible de manera predeterminada en un entorno convencional.
Esto sucede especialmente cuando hablamos de una plataforma que en el pasado se desplegaba en cualquier plataforma que estaba poblada con información como el nombre de la aplicación, versión, dominio, etc. Pero esto es complicado en un enfoque nativo de la nube. O tal vez no, pero al menos por algún tiempo, te has estado preguntando cómo puedes acceder a parte de la información que conoces sobre tu carga de trabajo nativa de la nube, para que la aplicación en ejecución dentro del pod también la conozca.
Porque cuando defines un nativo de la nube, describes mucha información muy relevante. Por ejemplo, pensemos en eso. Cuando inicias tu pod, conoces el nombre de tu pod porque es tu nombre de host:
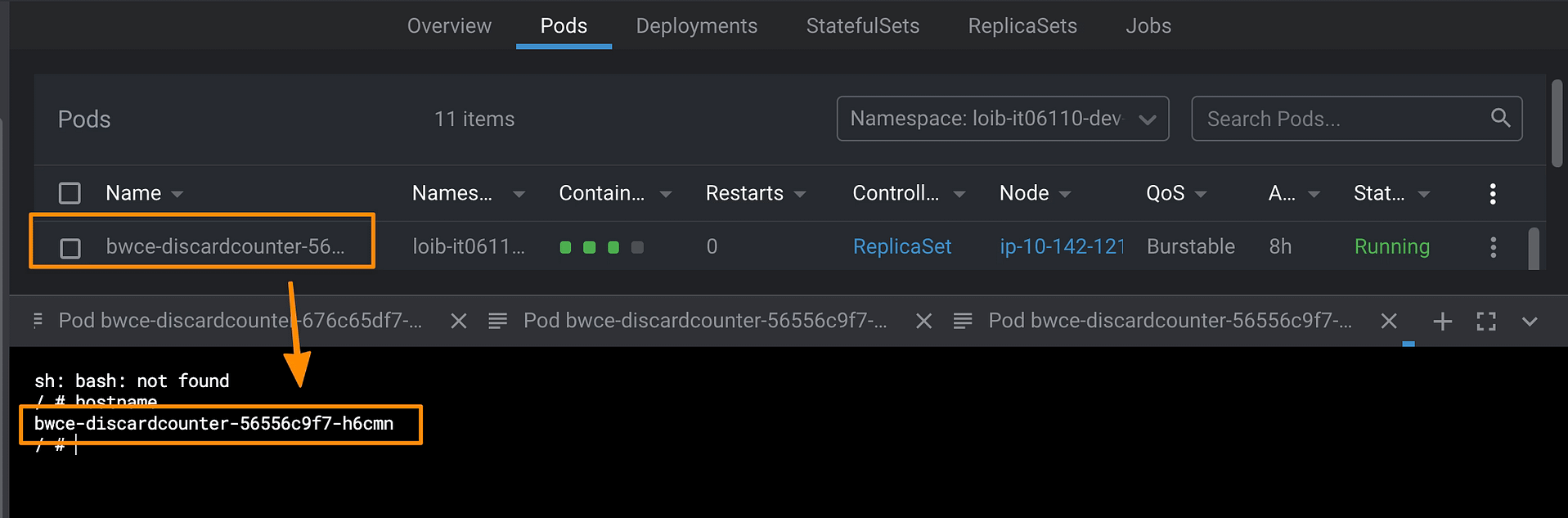
Pero cuando defines tu carga de trabajo, tienes un nombre de despliegue; ¿cómo puedes obtenerlo desde tu pod? ¿Cómo obtienes en qué espacio de nombres se ha desplegado tu pod? ¿O qué hay de toda la metadata que definimos como etiquetas y anotaciones?
Lo bueno es que hay una manera de obtener cada dato que hemos comentado, así que no te preocupes; obtendrás toda esta información disponible para usar si la necesitas.
La forma estándar de acceder a cualquier información es a través de variables de entorno. Esta es la forma tradicional en que proporcionamos datos iniciales a nuestro pod. Ya hemos visto que sabemos que podemos usar ConfigMaps para poblar variables de entorno, pero esta no es la única manera de proporcionar datos a nuestros pods. Hay mucho más, así que échale un vistazo.
Descubriendo la opción fieldRef
Cuando discutimos el uso de ConfigMap como variables de entorno, teníamos dos maneras de poblar esa información. Proporcionando todo el contenido de ConfigMap, en cuyo caso usamos la opción envFrom, también podemos usar valueFrom y proporcionar el nombre del configMap y la misma clave de la que nos gustaría obtener el valueFrom.
Así que, siguiendo el enfoque de esta sección, tenemos un comando aún más útil llamado fieldRef. fieldRef es el nombre del comando para una referencia a un campo, y podemos usarlo dentro de la directiva valueFrom. En resumen, podemos proporcionar una referencia de campo como un valor para una clave de variable de entorno.
Así que echemos un vistazo a los datos que podemos obtener de este objeto:
- metadata.name: Esto obtiene el nombre del pod como un valor para un valor de entorno
- metadata.namespace: Proporciona el espacio de nombres en el que el pod está ejecutándose como el valor
- metadata.labels[LABELNAME]: Extrae el valor de la etiqueta como el valor para la clave de entorno
- metadata.annotations[ANNOTATIONNAME]: Extrae el valor de la anotación como valor para la clave de entorno
Aquí puedes ver un fragmento que define diferentes variables de entorno usando esta metadata como el valor para que puedas usarlo dentro del pod simplemente recopilándolo como variables de entorno estándar:
env:
- name: APP_NAME
valueFrom:
fieldRef:
fieldPath: metadata.labels['app']
- name: DOMAIN_NAME
valueFrom:
fieldRef:
fieldPath: metadata.labels['domain']
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
Yendo aún más allá
Pero esto no es todo lo que la opción fieldRef puede proporcionar, hay mucho más, y si te gustaría echar un vistazo, puedes hacerlo aquí: