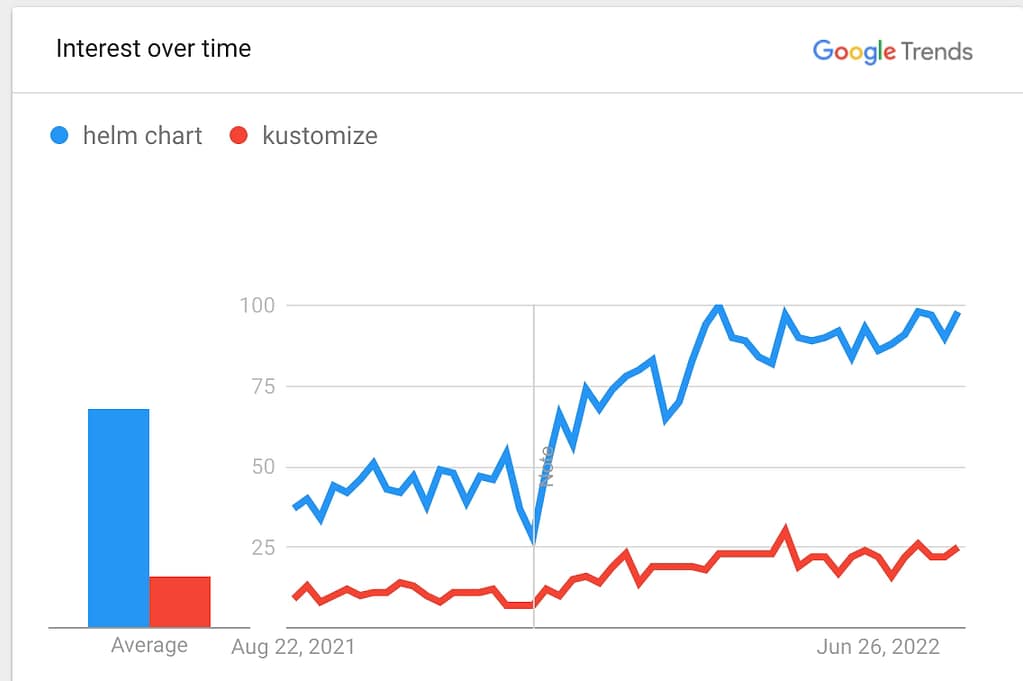
Introduction
Create secrets in Hashicorp Vault is one of the most important and relevant things you can do once you have installed Hashicorp Vault on your environment, probably by recovering and getting these secrets from the components they need it. But in today’s article, we will focus on the first part so you can learn how easily you can create secrets in Hashicorp Vault.
In previous articles we commented on the importance of Hashicorp Vault and the installation process, as you can read here. Hence, at this point, we already have our vault ready to start working with it wholly initialized and unseal to be able to start serving requests.
Create Secrets in Hashicorp Vault using Hashicorp Vault CLI Commands
All the commands we will do will use a critical component named Hashicorp Vault CLI, and you will notice that because all of our commands will start with vault. To be honest, we already started with that in the previous article; if you remember, we already run some of these commands to initialize or unseal the vault, but now this will be our main component to interact with.
The first thing we need to do is to be able to log into the vault, and to do that; we are going to use the root token that was provided to us when we initialized the vault; we are going to store this vault in an environment variable so it will be easy to work with it. All the commands we are going to run now are going to be inside the vault agent server pod, as shown in the picture below:

Once we are inside of it, we are going to do the log command with the following syntax:
vault login
And we will get an output similar to this one:
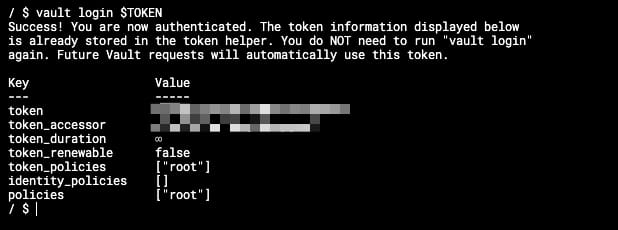
If we do not provide the token in advance, the console will ask for the token to be typed afterward, and it will be automatically hidden, as you can see in the picture below:

After this point, we are already logged into the vault, so we can start typing commands to create secrets in Hashicorp Vault. Let’s start with that process.
To start with our process for creating secrets in Hashicorp Vault, we first need to make or be more accurate to the Hashicorp Vault syntax to enable a secret path that you can think about as the root path to which all your secrets will be related to. If we are talking about having secrets for different applications, each path can be each of the applications, but the organization of secrets can be other depending on the context. We will cover that in much more detail in the following articles.
To enable the secret path to start the creation of secrets in Hashicorp Vault, we will type the following command:
vault secrets enable -path=internal kv-v2
That will enable a secret store of the type kv-v2 (key-value store in its v2), and the path will be “internal,” so everything else that we create after that will be under this “internal” root path.
And now, we’re going to do the creation of the secret in Hashicorp Vault, and as we are using a key-value store, the syntax is also related to that because we are going to “put” a secret using the following command:
vault kv put internal/database/config username="db-readonly-username" password="db-secret-password"
That will create inside the internal path a child path /database/config where it will store two keys:
- username that will have the value db-readonly-username
- password that will have the value db-secret-password
As you can see, it is quite easy to create new secrets on the Vault linked to the path, and if you want to retrieve its content, you can also do it using the Vault CLI, but this time using the get command as shown in the snippet below:
vault kv get internal/database/config
And the output will be similar to the one shown below:
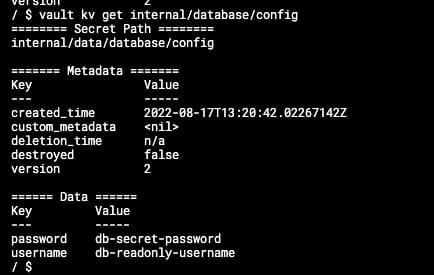
This will help you interact with your store’s content to retrieve, add or update what you already have there. Once you have everything ready there, we can move to the client side to configure it to gather all this data as part of its lifecycle workflow.
Create Secrets in Hashicorp Vault using REST API
The Hashicorp Vault CLI simplifies the interaction with the vault server, but all the interaction between the CLI and the server happens through a REST API that the server exposes and the CLI client consumes. It provides a simplified syntax to the user and translates the parameters provided into REST requests to the server, but you can use also REST requests to go to the server directly. Please look at this article in the official documentation to get more details about the REST API.