DevSecOps is a concept you probably have heard extensively in the last few months. You will see it in alignment with the traditional idea of DevOps. This probably, at some point, makes you wonder about a DevSecOps vs DevOps comparison, even trying to understand what are the main differences between them or if they are the same concept. And also, with other ideas starting to appear, such as Platform Engineering or Site Reliability, it is beginning to create some confusion in the field that I would like to clarify today in this article.
What is DevSecOps?
DevSecOps is an extension of the DevOps concept and methodology. Now, it is not a joint effort between Development and Operation practices but a joint effort among Development, Operation, and Security.
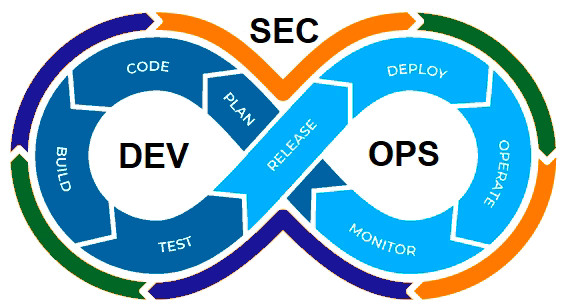
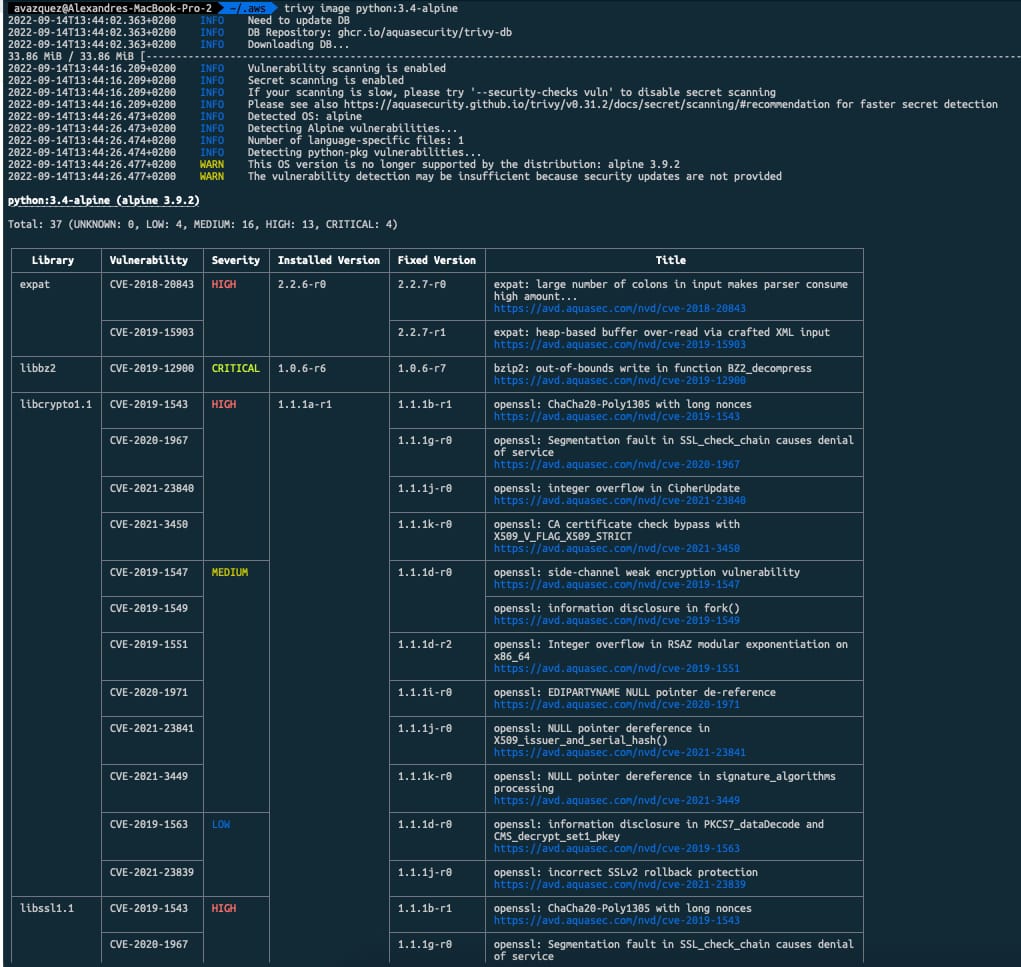
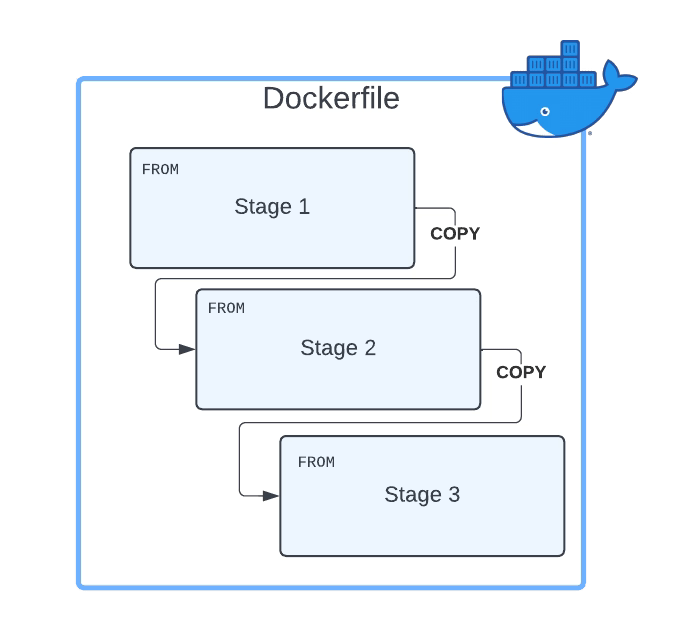
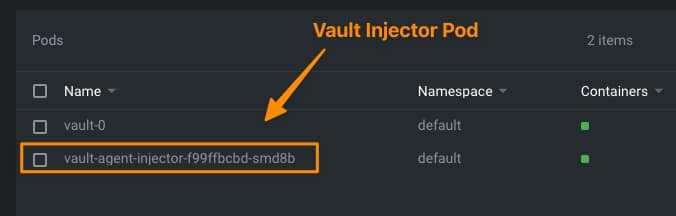
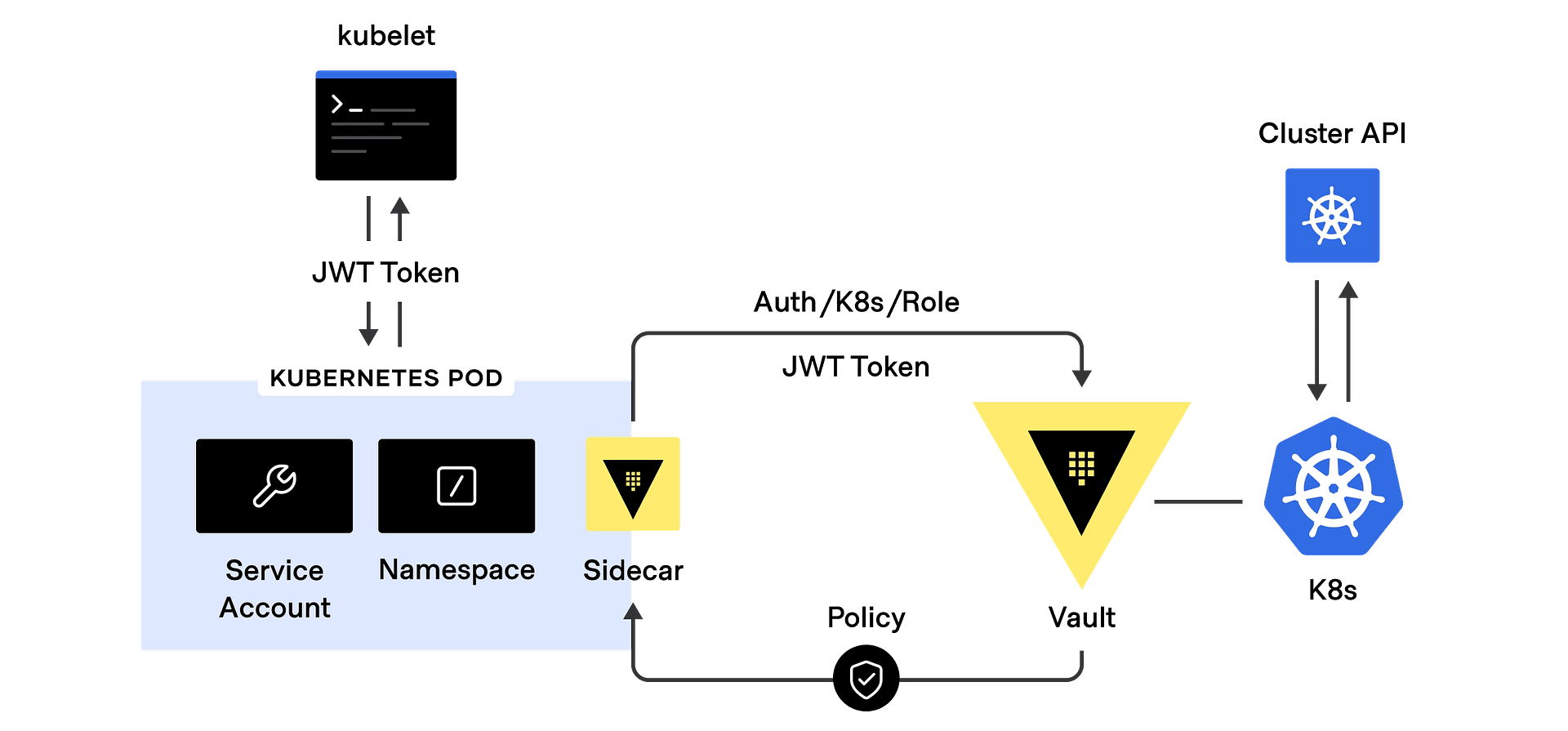
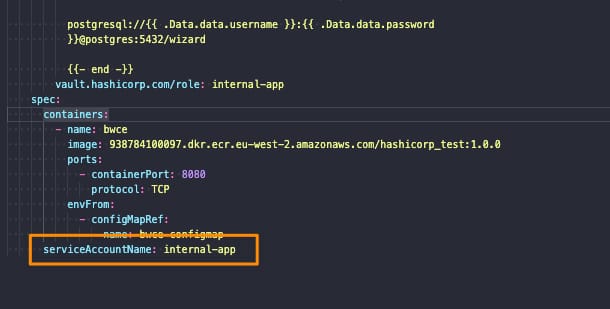
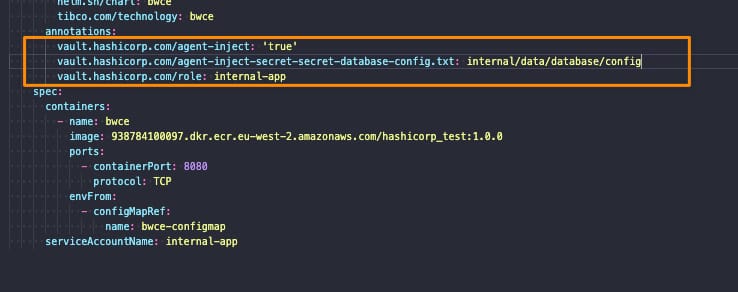
Implies introducing security policies, practices, and tools to ensure that the DevOps cycles provide security along this process. We already commented on including security components to provide a more secure deployment process. We even have specific articles about these tools, such as scanners, docker registries, etc.
Why DevSecOps is important?
DevSecOps, or to be more explicit, including security practices as part of the DevOps process, is critical because we are moving to hybrid and cloud architectures where we incorporate new design, deployment, and development patterns such as containers, microservices, and so on.
This situation makes that we are moving from one side to having hundreds of applications in the most complex cases to thousands of applications, and to have dozens of servers to thousands of containers, each of them with different base images and third-party libraries that can be obsolete, have a security hole or just be raised new vulnerabilities such as we have seen in the past with the Spring Framework or the Log4J library to shout some of the most recent global substantial security issues that the companies dealt with.
So, even the most extensive security team cannot be at pace checking manually or with a set of scripting all the different new challenges to the security if we don’t include them as part of the overall process of the development and deployment of the components. This is where the concept of shift-left security is usually considered, and we already covered that in this article you can read here.
DevSecOps vs DevOps: Is DevSecOps just updated DevOps?
So based on the above definition, you can think: “Ok, so when somebody talks about DevOps as not thinking about security”. This is not true.
In the same aspect, when we talk about DevOps, it is not explicitly all the detailed steps, such as software quality assurance, unit testing, etc. So, as happens with many extensions in this industry, the original, global or generic concept includes the contents of the wings as well.
So, in the end, DevOps and DevSecOps are the same things, especially today when all companies and organizations are moving to the cloud or hybrid environments where security is critical and non-negotiable. Hence, every task that we do, from developing software to access to any service, needs to be done with Security in mind. But I used both concepts in different scenarios. I will use DevSecOps when I would like to explicitly highlight the security aspect because of the audience, the context, or the topic we are discussing to do differentiation.
Still, in any generic context, DevOps will include the security checks will be retained for sure because if it is not, it is just useless. Me.
Summary
So, in the end, when somebody speaks today about DevOps, it implicitly includes the security aspect, so there is no difference between both concepts. But you will see and also find it helpful to use the specific term DevSecOps when you want to highlight or differentiate this part of the process.